字节跳动推出的「DreamActor-M1」是一项基于人工智能的视频生成技术,旨在将静态人物图像转化为超逼真的动态视频。该项目结合了先进的扩散变换器(DiT)架构与混合控制机制,在动画生成的质量、控制精度和场景适应性上实现了突破性进展。以下是其核心功能与技术特点的详细介绍:
一、核心功能与创新
- 静态图像动态化
DreamActor-M1仅需一张人物参考图像(如肖像或全身照),即可生成与驱动视频或音频同步的动画。例如,输入一张自拍照和一段舞蹈视频,模型能自动调整骨骼动作和表情,生成人物跳舞的逼真视频。 - 多模态驱动支持
• 视频驱动:通过分析驾驶视频提取面部表情、头部姿势(3D球体模型)和身体骨骼动作,并适配到参考图像上。
• 音频驱动:支持语音口型同步,可生成多语言对口型动画。
• 混合控制:允许独立调整面部、头部和身体动作,例如仅改变笑容而不影响姿势。 - 跨尺度生成能力
模型适应不同分辨率的输入,从特写面部到全身镜头均可处理,且生成质量稳定。例如,既能生成说话时的头部动画,也能处理复杂舞蹈动作的全身视频。
二、关键技术突破
- 混合引导系统
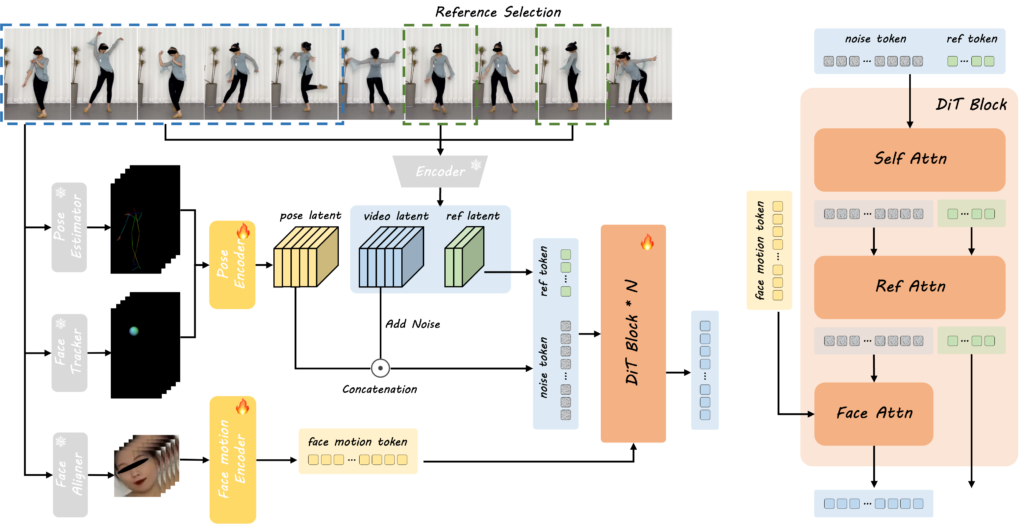
• 隐式面部编码:提取与身份无关的微表情(如眨眼、嘴唇颤动),避免复制驾驶者特征。
• 3D头部球体与骨骼模型:通过彩色球体编码头部旋转角度,骨骼模型调整身体比例,确保动作自然。
• 互补外观指导:当参考图像存在遮挡(如背面未显示),模型生成伪参考帧预测缺失细节,维持衣物纹理一致性。 - 多尺度与长期一致性
• 渐进式训练:分三阶段学习(身体/头部→面部→联合优化),提升复杂动作的生成稳定性。
• 多参考协议:检查过去多帧而非仅上一帧,减少长视频中的闪烁或变形问题。 - 架构设计
• 基于MMDiT扩散变换器,融合噪声分支与参考分支,通过交叉注意力机制整合面部表情、姿势和外观特征。
• 采用3D变分自动编码器(VAE)编码视频片段,实现时空联合建模。
三、性能优势与实测数据
- 质量指标:在FID(Frechet Inception Distance)、SSIM(结构相似性)等关键指标上优于Animate Anyone、Champ等竞品。例如,身体动画FID达27.27(竞品33.01–40.21)。
- 长视频稳定性:支持生成30秒(约750帧)连续动作,身份特征保持度达98.7%。
- 应用场景:
• 影视制作:用演员定妆照直接生成打斗片段,节省3D建模成本。
• 虚拟直播:支持200ms低延迟口型同步,提升虚拟主播表现力。
• 短视频创作:用户自拍+模板生成舞蹈视频,内测人均创作5.8个内容。