为什么需要突破性优化?
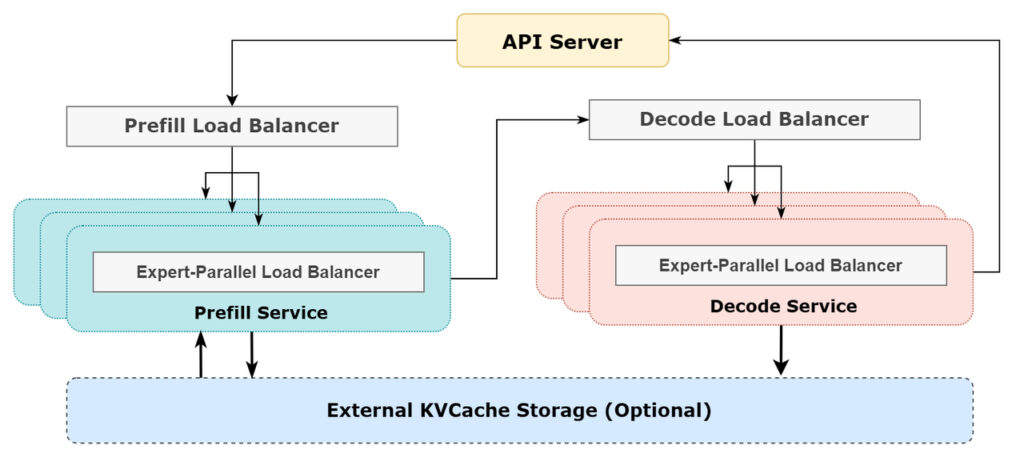
作为拥有256专家的MoE大模型,DeepSeek-V3/R1每次推理仅激活8个专家,这种高稀疏性带来了独特的工程挑战。传统单卡推理面临两个致命问题:专家计算批次过小导致GPU利用率低下,以及显存带宽成为性能瓶颈。我们的解决方案是:跨节点专家并行(EP)架构,通过突破性的系统设计实现每秒数万亿token的吞吐能力。
三大核心技术突破
一、超大规模专家并行架构
动态分级并行策略
- 预填充阶段:采用EP32+DP32混合并行
- 4节点部署单元管理32个冗余路由专家
- 单GPU处理9个路由专家+1个共享专家
- 解码阶段:升级至EP144+DP144
- 18节点部署单元管理32个冗余路由专家
- 单GPU仅需处理2个路由专家+1个共享专家
这种动态扩展能力使得单次推理的总体批次规模可达常规方案的18倍,专家计算批次充足性提升9倍。
这种动态扩展能力使得单次推理的总体批次规模可达常规方案的18倍,专家计算批次充足性提升9倍。
智能负载均衡体系
| 负载类型 | 预填充阶段优化 | 解码阶段优化 |
|---|---|---|
| 核心注意力计算 | 基于序列长度的动态分配 | KVCache使用量均衡 |
| 通信负载 | 令牌级负载均衡 | 请求数均衡 |
| 专家计算 | 专家热度感知调度 | 跨节点专家负载迁移 |
通过实时监测系统,我们在278个节点的集群中实现了<5%的负载差异率。
二、通信-计算流水线魔术
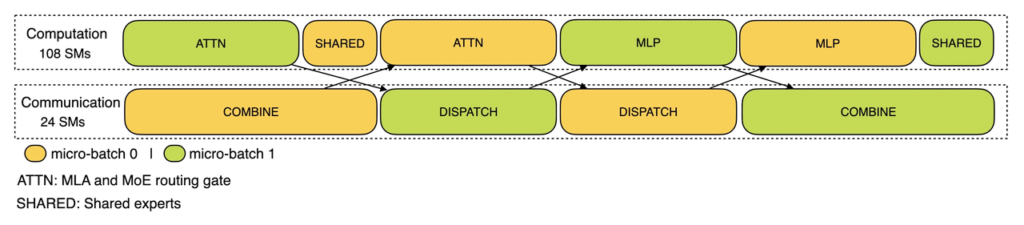
双微批次交错执行
将推理请求拆分为两个微批次交替执行,使得通信延迟完全隐藏在另一个微批次的计算时间内。实测显示,这种设计将H800集群的通信开销从23%降至4%以下。
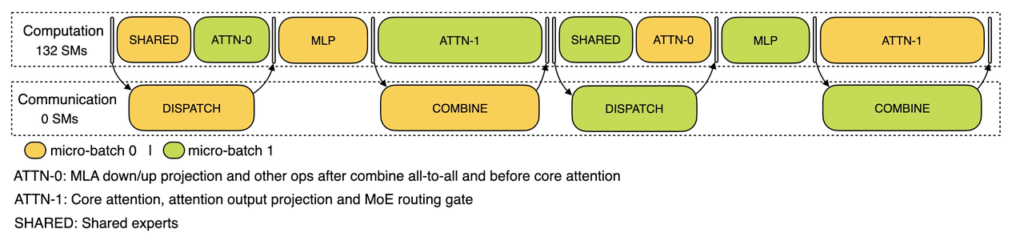
五级流水解码优化
<PYTHON># 解码阶段五级流水示意
for token in output_sequence:
stage1: 注意力层前半计算
stage2: 跨节点专家结果聚合
stage3: 注意力层后半计算
stage4: MLP专家计算
stage5: 结果回传通过将注意力层拆分为两个计算阶段,配合智能流水控制,即使在解码阶段也能保持92%以上的计算利用率。
三、超异构资源调度系统
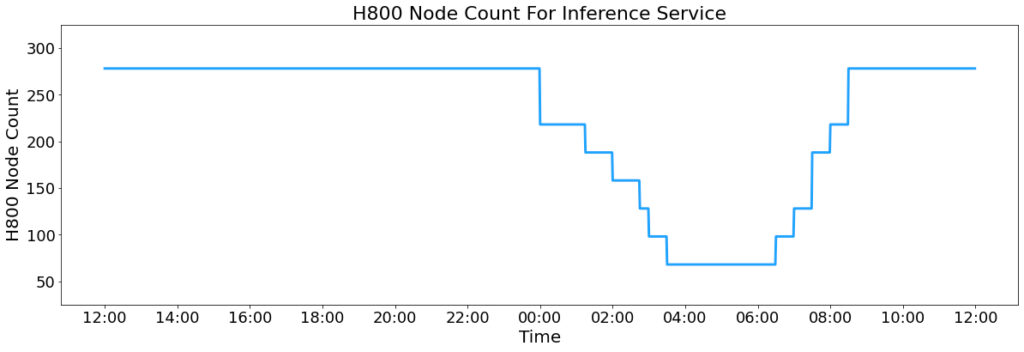
弹性资源调配
- 日间高峰:278节点全负载(2224块H800)
- 夜间低谷:自动缩容至1/3规模,释放资源用于训练
- 混合精度策略:
- 矩阵乘法/通信:FP8(与训练精度对齐)
- 核心计算:BF16(保持高精度)
成本效益奇迹
| 指标 | 24小时统计值 |
|---|---|
| 总输入token | 6080亿(56.3%缓存命中) |
| 总输出token | 168亿 |
| 单节点吞吐 | 7.37万token/s(输入) |
| 理论日营收 | $56.2万 |
| 实际运营成本 | $8.7万 |
| 成本利润率 | 545% |
未来演进方向
当前系统已在H800集群上实现单日超6000亿token的处理能力,但我们在以下方向持续突破:
- 专家动态迁移:实现跨物理节点的专家热迁移
- 三维混合并行:EP+TP+DP的立体化组合
- 量子化内存压缩:研发8bit KV Cache技术